KI Hardware
EYYES Layer Processing Unit
Der Einsatz von Deep Learning basierten Systemen in mobilen Anwendungen wächst rasant, insbesondere für fahr- und sicherheitsrelevante Applikationen im Verkehr und in der Industrie. Die Zukunft Künstlicher Intelligenz und auf neuronalen Netzwerken basierender Systeme sind weder CPU noch GPU oder TPU, sondern eine völlig neue KI-Chiparchitektur. Die Lösung nennt sich LPU – „Layer Processing Unit“ – und stellt einen Paradigmenwechsel in der Hard- und Softwarestruktur von neuronalen Netzwerken dar, den der europäische Technologieführer EYYES in seinen Produkten bereits auf den Markt bringt.
Mit einer Vervielfachung der parallel stattfindenden Rechenoperationen werden die Verarbeitungsgeschwindigkeit und der Datendurchsatz maximiert. Dies ermöglicht die Umsetzung besonders leistungsfähiger, energieeffizienter Systeme.

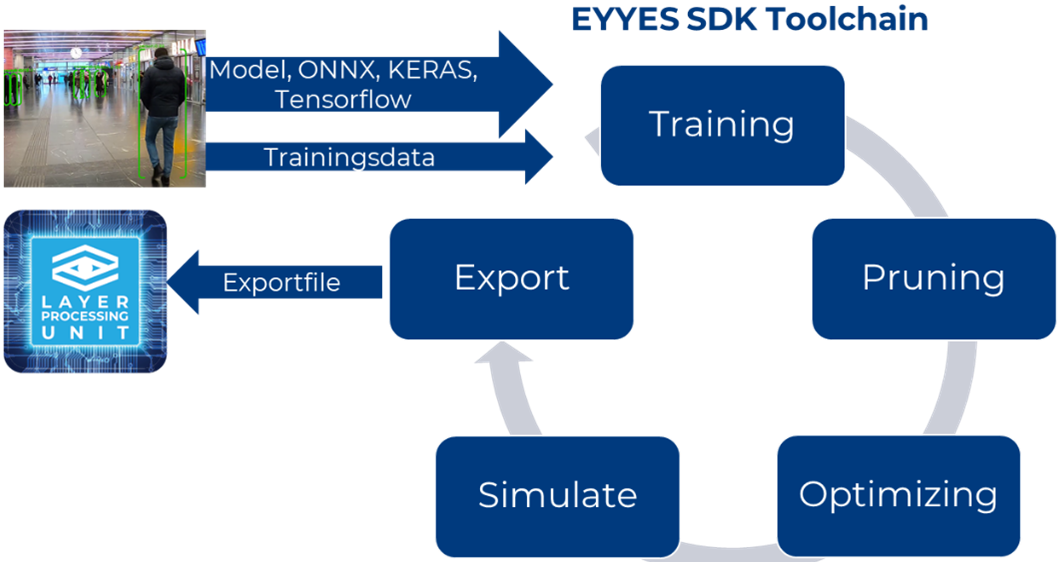
Wie funktioniert die LPU?
Als ersten Schritt gilt es die Neuronalen Netze entsprechend zu optimieren, damit sie überhaupt in einer Embedded-/Edge- Umgebung einsetzbar sind. Ziel ist eine Reduktion der Größe des Netzes und der benötigten Rechenoperationen ohne Qualitätsverlust.
Im zweiten Schritt erfolgt die Optimierung der parallelen Rechenoperationen im IP-processing core der LPU. Wie funktioniert dies nun im Vergleich zur GPU und TPU?
[servicebox_sc id=20357]
Der Vergleich mit bisherigen Technologien
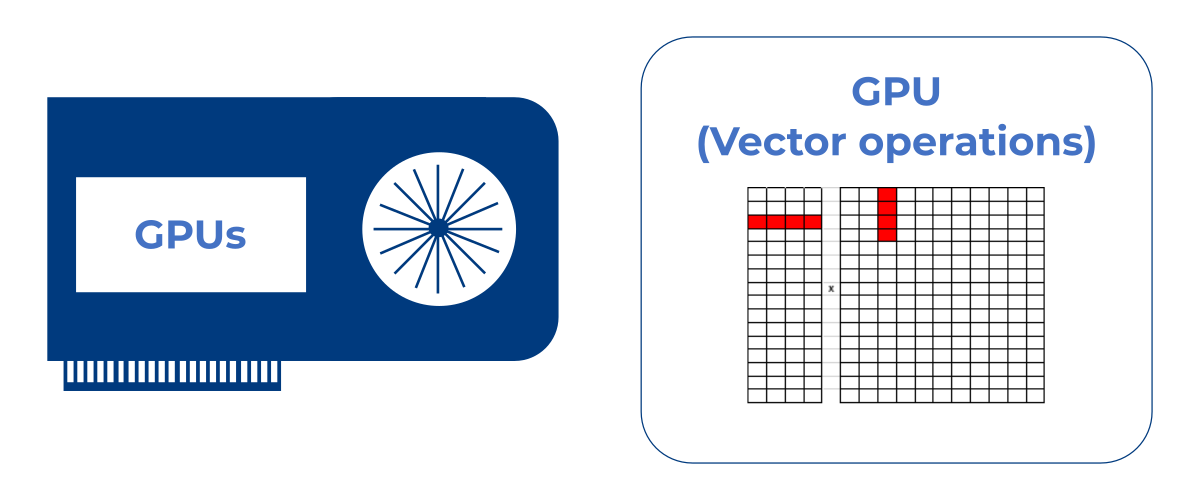
Eine GPU ist zwar schnell, kann pro Rechentakt aber immer nur eine Vektoroperation abarbeiten. Um die Layer eines neuronalen Netzes zu durchlaufen benötigt sie viele Taktzyklen, was hohe Rechenanforderungen und viele Speicherzugriffe zur Folge hat. GPUs sind daher für mobile KI-Anwendungen vergleichsweise ineffizient.
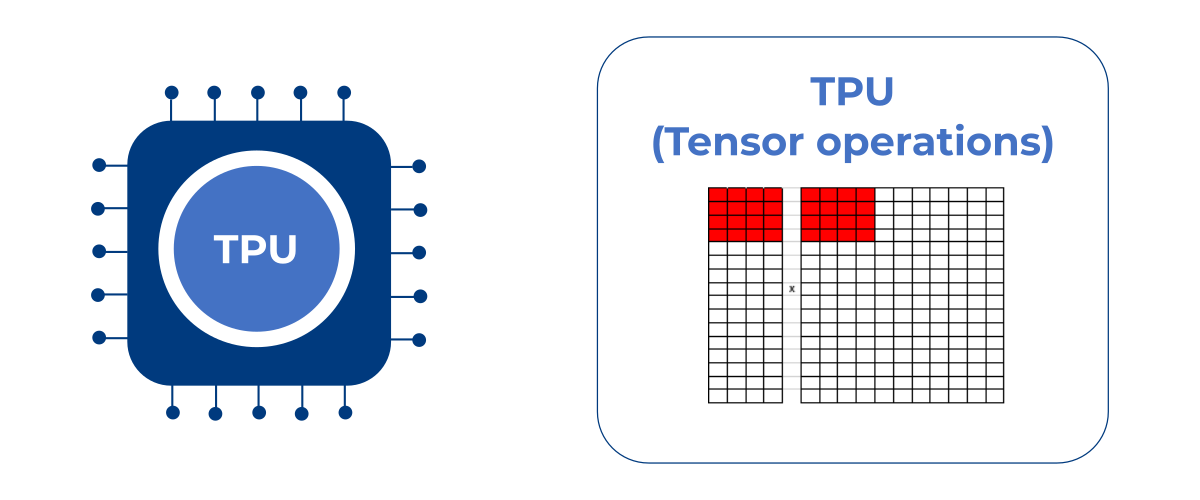
Eine TPU berechnet mit einem Tensor mehrere Vektoren auf einmal. Auch die TPU benötigt aber noch viele Rechentakte zum Zwischenspeichern und zur endgültigen Abarbeitung der Berechnungen aller Neuronen eines jeden Layers.
Die LPU kann in einem einzigen Rechentakt die Tensoren aller Neuronen in einem Layer eines neuronalen Netzes gleichzeitig berechnen, inklusive Addition der Ergebnisse und Berücksichtigung der Aktivierungsfunktion der Neuronen. Sie verarbeitet die eingehenden Daten parallel und führt Aktivierung und Pooling im selben Operationsschritt aus. Durch dieses patentierte Verfahren kann die LPU auch bei geringen Taktfrequenzen die benötigten Milliarden an Rechenoperationen hocheffizient abarbeiten. Sie ist damit eine hocheffiziente Chip- bzw. Prozessortechnologie für Embedded KI-Anwendungen.
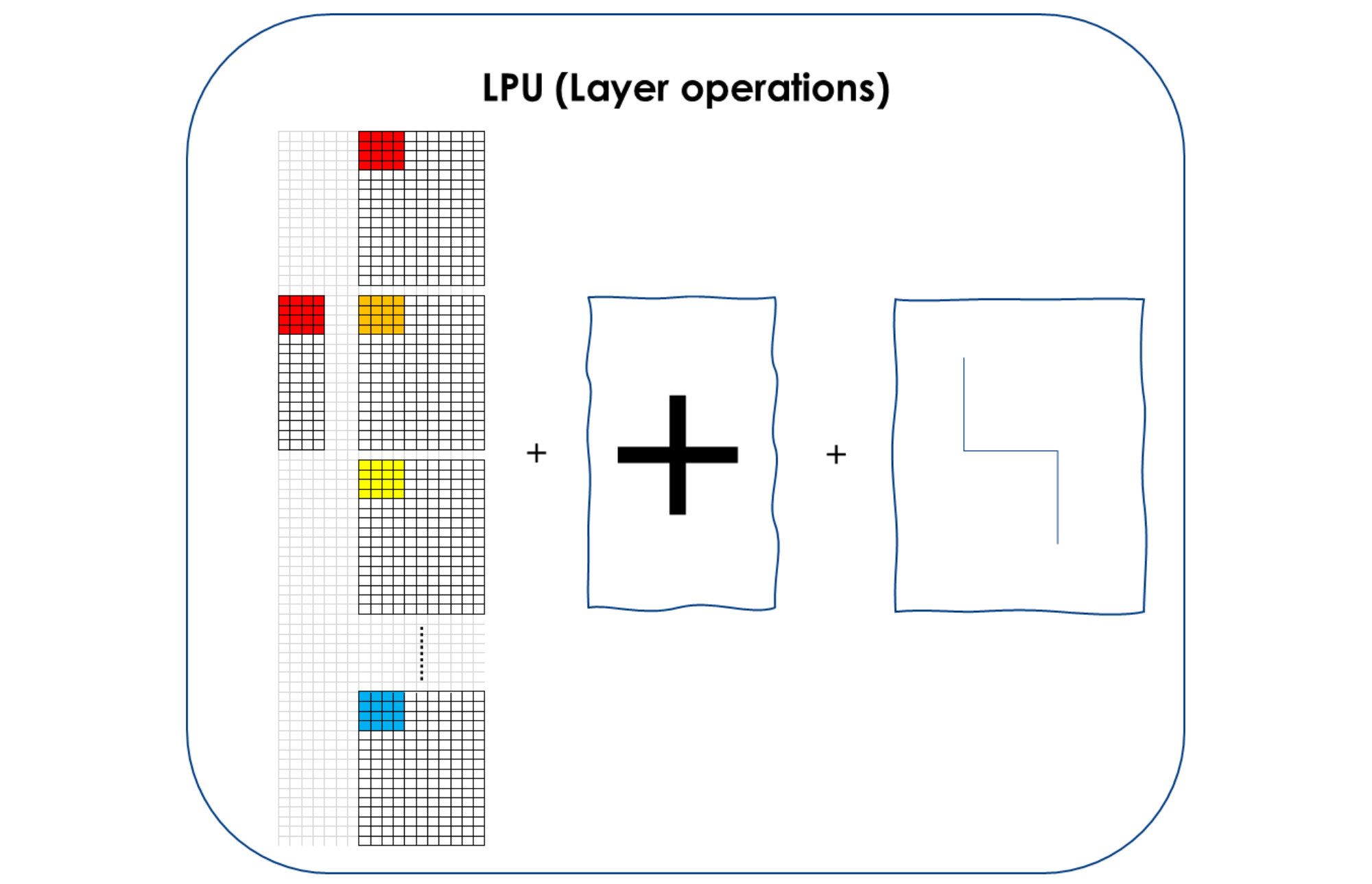

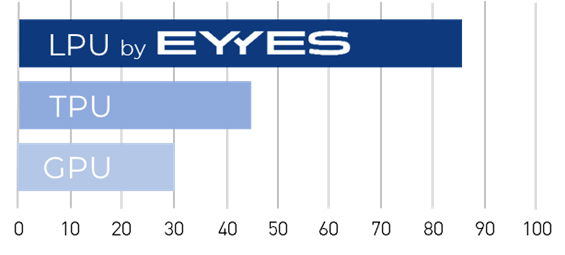
Die parallelen Abarbeitungsprozesse sind der wesentliche Unterschied zur Arbeitsweise von Grafik- und Tensor-Prozessoren. Die Performanceverbesserung durch diese simultan ablaufenden Rechenoperationen bringt den revolutionären Vorteil: Bei vergleichbarer Implementierung in Form von Taktfrequenz und Chiptechnologie liegt die Performance mindestens 3 mal so hoch wie bei einer GPU und doppelt so hoch wie bei einer TPU, wie die nebenstehende Vergleichsgrafik eindrucksvoll zeigt.
System on Module mit integrierter LPU
Das Real-Time-Interface 3.0
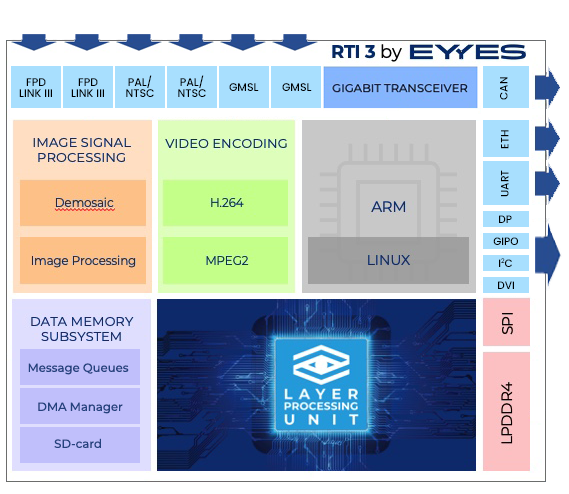
Aufbauend auf der Layer Processing Unit Architektur, entwickelte EYYES das Real Time Interface 3.0 (RTI 3.0). Dabei handelt es sich um ein System on Module zur visuell basierten Objekterkennung, das für unterschiedlichste Anwendungsbereiche eingesetzt werden kann. EYYES erreicht bei voller Ausnutzung der Fläche des Xilinx Zynq 4 MPSOC FPGAS die enorm hohe Rechenleistung von 18 TOPS auf einem kleinen Board von 67mm mal 58mm. Im Vergleich zu SOMs mit konventionellen TPU Verarbeitungsprozessen zeichnet sich das RTI 3 durch geringe Hardwarekosten, eine besonders hohe Energieeinsparung von rund 25% sowie die flexible Nutzung in unterschiedlichsten Anwendungen aus.
Das Modul ist in der Lage, zwei unabhängige Full HD-Videostreams zu verarbeiten und an unterschiedliche Interfaces auszugeben. Seine hohe Flexibilität ermöglicht zudem maßgeschneiderte Kundenentwicklungen und die Integration über LINUX-Treiber z.B. für autonome Fahrassistenten.
Die custom on the shelf (COTS)-Funktionalität des RTI 3.0 sorgt dafür, dass bereits bei der Auslieferung alle Basisapplikationen zur Objektdetektion für Personen und Fahrzeugerkennung implementiert sind. Das RTI 3.0 ist damit ein führendes System für sicherheitsrelevante Verkehrsanwendungen, das höchste Leistung mit effizientester Performanceausnutzung kombiniert und damit bisherige SOMs in punkto Energieeffizienz, Skalierbarkeit und Einsatz-Flexibilität weit hinter sich lässt.
Anschlussübersicht des RTI 3.0:

